An award-winning graphic designer, an independent game developer, a self-published novelist, a movie and video game critic, and everyday artist. Matthew VanDevander lives in the great state of Tennessee and is on a never-ending quest for the deeper meaning of life.
Over the course of making Taiji, I’ve designed many more puzzles than what have survived into the game as it exists today. Most were cut because they just weren’t very good. But there were some decent puzzles that had to be removed because there was no good way to fit them into the existing areas; they took up too much physical space or dragged out the pacing too much.
So for the past couple months I’ve curated those puzzles into a hidden bonus area. There are also a few puzzles that were custom built for this area to round out some of the missing spots in the overall design.
Finishing this area is a major milestone, and means that the game is basically gameplay complete. With that said there are still several major things that I need to do before the game can be shipped. And one of those is to playtest the game a decent amount. I sent out beta invites to several long-suffering volunteers over the past week and have been getting a lot of good feedback so far, and fixing a lot of bugs.
This next week, if the bugfixes become more manageable, then I will start working on an announcement. So look forward to that in a couple weeks, hopefully. In the meantime enjoy these screenshots of the new area.
This post is adapted from something I wrote in the Taiji Discord, but I thought it might be interesting to share it here. By the way, you should totally join our Discord if you haven’t already.
Discord user GingerBread asked: “is there a specific reason why you chose tile shading as a basis for your puzzles instead of line drawing for instance? Was it mainly not to be too close mechanically with the Witness, or did you have other motivations?”
My Answer
The puzzle mechanic came about a bit differently, in that the game didn’t start as a Witness-like game.
— ᴍᴀʀᴛɪɴ • 76/ʜᴀʟᴛ • ᴄᴏʜᴇɴ (@martin_cohen) May 13, 2015
Initially Taiji started out in April or May of 2015 as a sort of reimagining of a what a Zelda game could be. I was working with a very talented artist and musician named Martin Cohen and we were just calling the game ZG (for Zelda Game) back then. This was before Breath of the Wild was ever revealed in detail and I was sort of thinking about what a more modern Zelda game might be like: open world, non-linear, hard combat, and one of the things I thought would be good was to have some sort of core puzzle gameplay. (This obviously all ended up being done by Nintendo in their forthcoming game but anyway it was the headspace I was in at the time)
I had initially started work on combat design and some world design ideas, but I realized that I didn’t have any experience with combat design and was having a hard time making progress there at something interesting in a prototype form. So, I decided that I would switch focus and try to come up with something for the puzzles. I had many years of puzzle game design experience already so I thought it would be easier to make headway there.
I was not setting out to do something explicitly similar to the Witness, although I was inspired somewhat by Jonathan Blow talking The Witness having “core puzzle gameplay.” For example, a first person shooter has the core gameplay that you shoot enemies and dodge their attacks. This core gameplay gets repeated over and over across the game, but because of the depth and variation within that core gameplay the game doesn’t get boring just because you’re “doing the same thing over and over”.
Most Zelda games do not have core puzzle gameplay. Although they are not as bad about this as point and click adventure games, they do tend to have disconnected puzzle designs that at best maintain a theme across a single dungeon, and at worst are complete one-offs.
So I knew that I wanted to have some sort of core puzzle mechanic that the player would engage in across the whole game, but that would still have enough depth to stay interesting. The concept for the puzzles being about toggling things into some sort of pattern really just came to me, so unfortunately there’s not a cool story for why I thought of that. But the initial idea was a little different than what it eventually became and was more like the Mattel game Lights Out (a game which I had never heard of at the time). So you would toggle a tile and it would also toggle its neighbors.
So I made a little prototype of that and it seemed interesting. However because I imagined that the goal would always be to just light up the whole grid of tiles, I didn’t think there was tons of depth in that mechanic alone. Instead I imagined that the game would have variety through different input methods. So I also implemented some “snake” type puzzles where you would be forced to fill the grid by drawing out a path (this type of mechanic is still in the game in a few spots).
This still wasn’t that interesting, so I instead started thinking about how I might clue the player into different things to put on the grids. I came up with a couple puzzle sets that I thought were itneresting (both of which are in the game still in a somewhat evolved form), and I felt like I was really getting somewhere.
Unfortunately, I still had not figured out anything about the combat, and I also felt like the puzzle design would really take some time to flesh out (I didn’t imagine it would take 5 years). But because I knew I was onto something really interesting, I wanted to spend as much time as possible prototyping the gameplay before really committing to anything. So I suggested that Martin take a break from doing art and music concepts at least until I had developed this part of the gameplay further. (Ultimately I decided that I would pursue the project solo, though this in no way discounts Martin as an artist and musician, and I enjoyed working with him immensely. It had much more to do with my fear of relying on anyone else, but that’s a story for another time perhaps)
So I shelved the combat and focused on puzzle design for a while. I designed a set of puzzles that let the player just toggle things in a free form way with no particular constraints (this was just going to be another one of the interaction methods at this point). Suddenly it was nearing the end of 2015, I had a growing document full of puzzle ideas, and soon a game that I had been anticipating for nearly 7 years would be released.
That game was The Witness, and my hype level for the game was somewhere above what was reasonable for a jaded 26 year old man. I thought that the game might (just maybe) turn out better than Braid.
I just happened to be laid off of work when The Witness released and I played it all day every day for a week until I had seen everything it had to offer me. I was blown away. Not only did I find it better than Braid. Not only was it the best game I had ever played. I thought perhaps it was the best puzzle game possible.
I was elated, but I was also devastated. Much to my surprise, almost all of those exciting gameplay ideas in that document I mentioned earlier were also in The Witness in stunning fully developed forms that were much better than anything I could have done.
…what was I going to do now…?
I felt for a time like there might be no point in what I was making. It felt both too similar and and also lesser. I recall an email chat I had with Brian Moriarty around this time where he commiserated with my feelings of burgeoning irrelevance, and opined that Jon had “made Salieris of us all”. (Don’t know who Salieri is? Feel free to google it, but honestly that’s kind of the point)
However, I picked myself up off the ground and resolved to continue forward. Although The Witness had well mapped the territory ahead, I felt I could use it as a guidebook on what types of things would work in this kind of game and when there was overlap between the ideas, look for different forms of those ideas to the form they took in The Witness. I set out to make Taiji into a game that was both similar to, and different from, The Witness.
If The Witness was a telescope with which one could peer out at the universe and see certain ideas, I began to see Taiji as a different telescope with a different vantage point with which to look at some similar ideas. There was value in the different perspective even if sometimes the subjects were similar
With that said, one of the big things I chose to copy from The Witness was the symbols on the puzzles that you slowly discover the meaning of through experimentation. This ended up forming the bulk of the gameplay depth of the game, and I have been relatively happy with the degree of overlap and separation between the two games puzzle ideas.
Eventually as the game developed further, I felt like the alternate puzzle interaction methods were the least interesting things in the game. Also because those puzzles were just about space filling with no symbols or environmental cues it was casting this doubt on all the other puzzles that “oh maybe I just fill it all in?”
So the “lights out” type puzzles and the space filling stuff in general was cut from the game. And I also gave up on combat. (The Witness + Combat could still be interesting, but Taiji is not it) So the final game now focuses on puzzles where you can freely toggle tiles, and there are a few snake type puzzles that use a different interaction method where you’re walking on the puzzle in order to toggle the tiles.
I don’t know if that answers the question about how I chose tile shading, but hopefully it was a fun story!
Since the prior post, the pixel art for the Mill area has been fully completed and I’ve been chopping everything into assets that can be assembled in game. Below, you can see the finished pixel art as well as the current state of integrating it into the game:
You may notice the colors are a bit different in the in-game version (particularly red). This is because the game uses a color grading setup that is not optimized to any particular area in the game. Ideally before release I’ll go through and tweak the color grading a bit for each subarea to lock in a more unique look. If I can’t afford to do that though, I don’t think it looks too bad as it is.
Either way, there is clearly an empty space on the right hand side of the area that needs to be filled in!
The reason the finished art has that empty space is because I will be assembling that section using existing assets from the Shrine area, as it is a mechanical mix-in with the puzzles from that area, and the art for that area was created very modularly.
So, baseline art implementation is around 80% done or so. I still have to implement the exteriors, add some moving parts and add the entrance path below the plateau area to the left. After that I’ll have to add in all the collision and triggers, which is another whole bucket-load of work, but at least everything seems to be proceeding straightforwardly.
I will be very happy to be finished with this area and be focused on tying up the last little loose ends so this game will be ready for release. That’s not to say that I have a firm idea of when the game will be done. Although I think it could still possibly ship before the end of the year, it’s likely to slip somewhat into next year. Thanks for your patience on that front, I’m trying to get things done as quickly as I can.
I know some folks are probably following the written devlog and not the video devlogs, and I’ve been a bit more diligent about putting out those than I have been over here. I apologize for that. I often am remiss to simply post the same information over here that’s in the videos, as it feels redundant, but I think having some updates is better than going a whole month (or two!) without any sign of life.
I’ve finished up both the the sketch from the previous dev log post as well as a more detailed pass on the concept art for the Mill area. With that out of the way, I have been moving onto doing the actual in-game pixel art. In order to save some time, I’ve combined both the pixeling and the “decay” pass on the art into the same phase.
You can look at all 3 passes as they currently exist (including the incomplete pixel-art pass) below:
Doing the pixel art is taking some time because there are a lot of small details which I want to get right with this area. As I mentioned in thelatest video dev log, there is an important balance to strike between things having enough rust, dust, and decay, and things remaining within the overall “flat” aesthetic of the game’s art style. With that said, I think the hardest part is now out of the way and I’m onto the more straightforward implementation phase.
I enjoy detailing the pixel art much more than I enjoyed planning everything out. I think this probably comes down to me being a generally detail-oriented person, ever since I was a small child. Probably something to do with being a bit autistic. I don’t know for sure, but that’s how it is.
Looking at the big picture, this is the final major area that needs to be finished. After that, there is a bonus area that I want to add as well, although it will be less visually detailed and hopefully can be completed in short order.
I’m getting closer than ever to actually having the game finished to a baseline degree. Ideally I’d like to go back over everything and add in more details and clean up stuff that I’m not happy with. But we’ll see how much I can actually afford to do. The main obstacle at this point is how little money I have left. Although I have managed to reduce my burn-rate rather significantly for the time being, I’m about one small disaster away from being totally broke.
Anyway, not trying to complain, just trying to air out some of my thoughts here.
I feel like I should cover something a bit more in-depth here on the blog soon. If anyone has any suggestions for something to dive deeper into about the game, feel free to leave them in the comments below!
Gosh, time sure does fly when you’re making a game. I seem to have let June slip by without an update here. Although I have kept up with the video devlog series over on the YouTubes, I recognize that some folks just like to read a little more than they like to look at my beautiful face and unkempt mane.
I’ve been fixing up small things around the game that have been annoying me for a long time. There’s still bunches left undone on the “nice to have” list, but I’ve tidied up some important ones. Mostly I’ve been doing this because the progression on the artwork for the Mill area has been going a bit slower than anticipated (even though every time I do an area I anticipate it will take more time than the last!)
Part of the delay has been from doing some design revisions to the overall flow of the area. I mentioned these plans in the previous post, but I wasn’t expecting that the structural changes to the area would require so many puzzle design changes as well. It turns out that when you are planning on having an area be mostly knowledge-gated, you have to design puzzles that are specific to this purpose. Good knowledge-gates put up an initial barrier of complexity, but then fall rather quickly if the player has the pre-requisite knowledge.
Who’d have thunk that a good knowledge gate is one that gates mostly on knowledge!
In addition to this, I felt like there were a few small ideas in the area that could use a bit more polish in how they are delivered to the player. One of my favorite things in puzzle games is when I’m put in what seems like an impossible situation, based upon everything I’ve come to assume about the mechanics of the game. But the design or layout of the puzzle allows me to deduce that some move that was previously unknown to me must be possible. So, I have been doing some redesigns to create that type of experience. Requiring the player to guess that there is some emergent behavior of the mechanics that is non-obvious rather than giving them a simple situation which just illustrates it.
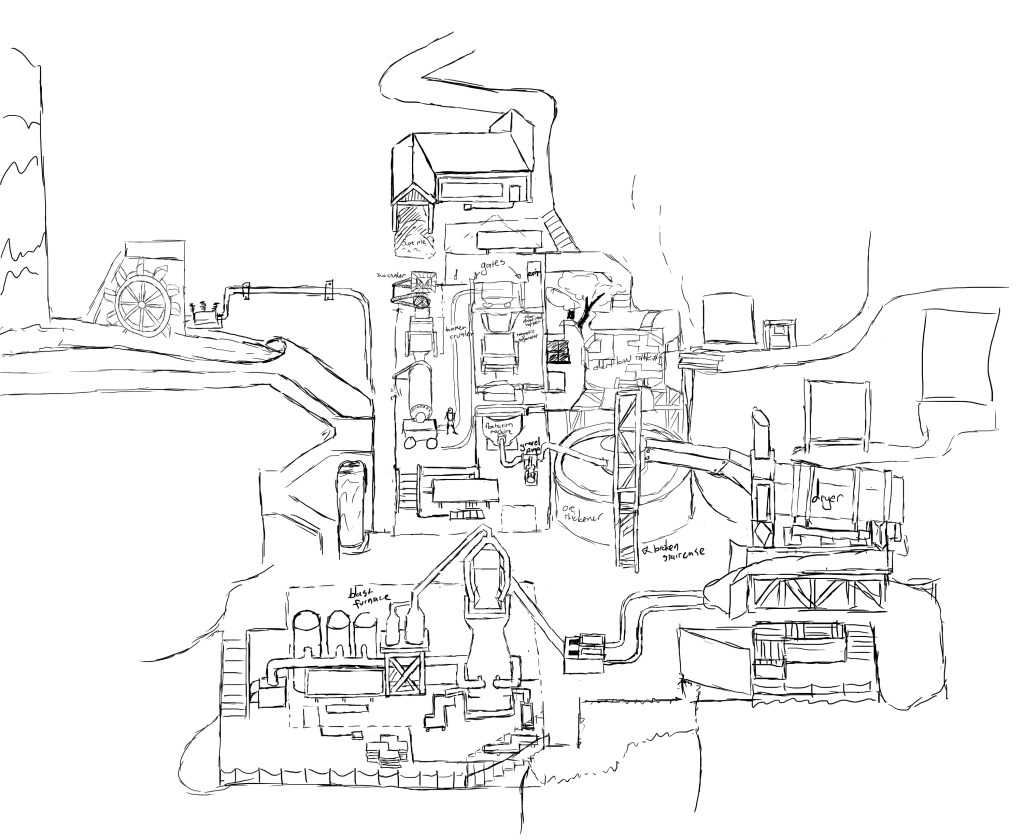
At this point, I’m fairly happy with the puzzle set for this area, and I think that the flow of ideas will work well. So I’ve spent the past week or so sketching out some rough ideas for the visuals. This has required me to do a lot of research on different types of machinery so that I can hopefully create something a bit plausible as a functional space.
Concepting is still a work in progress and things are subject to large changes, but here are some things that I’ve drawn along the way so far.
Things are finally progressing! I finished up the endgame area a week ago and shipped that out to a small group of testers. I believe there will still be some changes/improvements there, but overall I’m happy with the initial feedback I’ve seen.
Experience has shown me that when I take this long between builds of the game, major things will end up broken. Because of that, I’ve been taking a little downtime between shipping this build and implementing the next major area for the game. I didn’t want testers finding game-breaking bugs while I’m ripping up so much that I can’t ship a build until I finish the art for the next area.
Thus far, The bugs have definitely started to flow in. In fact, I’ve not been able to address the endgame area feedback as much as I’d like because there were so many other bugs. But it’s good to have my decision to postpone major changes validated.
In the meantime, as part of my break from game-breaking work, I’ve completed one of those “nice-to-have” improvements on the list; something I thought I might not be able to get done before ship: I’ve been re-doing some of the art for the starting area. You can see a couple comparisons below:
It’s hard to believe it’s already been two years since I originally did some of this artwork, but it’s been in desperate need of improvement for a while. I think the revision has much stronger details while also having a cleaner look that fits better with the rest of the game’s aesthetics.
It’s also a bit of a testament to how much I’ve improved as an artist over the course of this project. When I first started doing the art, I really didn’t know if I’d be up to the task. I’ve done some dabbling in visual art through my life, but I’ve never considered it something that I was particularly strong at. But through a combination of thoughtful art direction choices and just churning away for years on end, I think I’ve achieved something that looks nice and works well for the game.
So, What’s Next?
As I mentioned in the previous post, the next major task on the list is the artwork for the Mill area. I also need to re-think the structure of the area significantly. The current implementation is too straightforward and boring:
As you can see, most of the area is just a straight line. Although there is a bit of branching in the middle, the puzzles on the left side there are completely optional, so the main thrust of the area is totally linear. This structure, combined with the sheer number of puzzles in this area (44 essential, 25 optional), can be pretty exhausting for players to go through, and although adding artwork to the area can help significantly with the fatiguing aspect of the experience, I also want to try some other things.
I’ve experimented a bit with the structural designs for each area as I go along. I always try to do something a little different. Some areas are very linear, with a straight line of puzzles you have to all do in order. Some are mostly linear but with a few splits that you can do out of order. Some are almost entirely non-linear, with many options that are equally challenging.
One of the things I’ve thought about doing with the Mill area is designing it a bit “backwards”, with the player finding the hardest puzzles in the area before the introductory panels. This could backfire horribly, since some players may assume they should be able to solve anything that’s accessible to them, but it fits into my plan to go for a much more non-linear and knowledge-gated approach to this area than I have achieved with any of the others.
By “knowledge-gating”, I’m referring to the concept that the only barrier to progress is that you don’t understand how to do something, rather than requiring the player to obtain some item, or solve a long set of puzzles elsewhere.
Perhaps the area will be split into several buildings which can each be entered by solving a difficult puzzle. Each of these difficult puzzles will require some knowledge gained elsewhere in the area. This means that the player will have to explore around a bit when they first enter the area before they find a puzzle they can gain some traction on, but hopefully it will create that fun experience where the player realizes, after learning some new concept: “Aha! I know how to do that other puzzle now!”
I always try to push myself to do better with every new thing I add to the game. It’s what keeps this project engaging and enjoyable for me over such a long development cycle. (coming up on 6 years now!) Unfortunately this does mean that each new area has tended to take longer than the previous one, but I’m excited to get started on the Mill, and I think it has potential to be one of the better areas in the game.
I am still working on the Endgame area. I had hoped to be done with it by the end of last year, if you can believe that. So I would say things are progressing quite a bit slower than anticipated. With that said, the puzzle design for this area is now complete, as is most of the art, so I’ve just been assembling the pieces that I’ve created. Wiring up the bits and the bobs, so to speak. I’ve been doing a lot of this on stream, compromising a bit on my desire to keep everything about the Endgame unspoiled, but I think it’s more important for me to be able to focus and get the Endgame area done as quickly as I can.
Here’s a spoiler-free screenshot of some of that:
Once I finish the Endgame, there’s really only one large task left on the list, which is the Mill. So, in spite of being behind schedule, there’s still a decent chance that I can ship the game roughly on time. As I regretted in the previous devlog post, I do wish there were more time for me to polish up stuff and re-do bits I’m not as happy with as I could be. But alas…
One major thing that I’ve had to cut is simultaneous console ports of the game. The current plan is for the initial release of the game to be PC only, and then I will do one unannounced console port as soon as is reasonable. It would help me a lot with determining where best to focus if you would answer the following poll.
Getting work done is almost entirely about managing one’s own psychology. It’s always true throughout the development of any long-term project, but perhaps even more true when one is getting closer to the finish line; You have to maintain a state of mind where productive work is possible before any work can get done.
Recently, I’ve been feeling a bit depressed, both because of the protracted amount of time the endgame design is taking, and the slow dawning realization that the runway is getting shorter and I soon will have to, to a certain extent, abandon this project. I don’t mean to suggest that I’m giving up, but instead that no project of this magnitude is ever truly finished, it is just abandoned, and perhaps released on Steam at the same time.
It’s an interesting thing, since I should probably feel proud of how the game has come along. I have had several playtesters talk with me at length about how much they enjoyed the game, even in its various incomplete forms. As the game takes a more developed shape, these conversations have become more frequent. However, Taiji will always exist for me more as an idea than an actual thing I’ve created. An aspiration and a hope more than an artifact.
In that sense, I am disappointed in the game and I see myself as a failure. I have seen infinite potential and I have only managed to grasp at what I could reach. The limitations of both my ability and my time creep up on me as the project approaches something like a finish line. I still want so much more for it, but it isn’t practical to keep working on it forever.
Since you’re reading this on the development blog, you’re probably already aware; but I freshened up the home page to be cleaner and more informative for newcomers. There’s also some nice links at the bottom to all of the places you can find Taiji around the internet.
Speaking of which, you can now join the Discord group and chat with other folks who are excited about the game. We’ve got room to grow, so I hope you’ll consider joining our little community!
If you have any suggestions or complaints about the website or the discord group, then you can leave a comment on this post or talk to me on Discord and I’ll see what I can do!
Working on The Endgame
Taiji’s ending involves some puzzle concepts that I don’t want to spoil, so this article will be spoiler-free as far as Taiji is concerned. However, I will need to discuss some other game’s endings for context. Spoiler sections will be marked if you want to skip them, you may be able to pick up enough with context.
Because I want to keep the ending a surprise, I haven’t been able to work on it on my livestreams. But bouncing between working on art for the livestreams and working on the endgame prevented me from being able to do the type of Deep Work necessary to get the ending right.
However, as I’m heading into what should be the final year of development, it is urgent that I have this part of the game design worked out, so I’ve been taking a bit of a sabbatical from livestreams so that I can focus on getting the ball rolling here. This past week has involved dusting off some code that I haven’t touched in almost six months.
What Makes a Good Ending?
Making a satisfying ending for any video game is a challenge, but I think I puzzle games are a particular enigma. With action games it can often suffice to cap things off with a particularly difficult boss battle. But what is the equivalent of a boss battle for a puzzle video game?
The most straightforward interpretation might be to simply have a really hard puzzle to cap things off, but this is a fundamental misunderstanding of the role that boss battles serve. Boss battles are not simply “the normal gameplay, but harder.” Instead they offer a different type of gameplay than the rest of the game. The boss enemy will usually have complex movement patterns that require memorization, and may change over the course of the fight, or perhaps the environment will become involved in the battle in a way that it previously hadn’t.
The important takeaway is that satisfying endings require a change-of-pace. There ideally needs to be a shift in the gameplay style, context, and intensity. How you choose to accomplish this is really up to you, but the point is that although a hard puzzle may suffice for the ending to a smaller subsection of your puzzle game, it cannot be relied upon on its own to create a satisfying final coda.
So, let’s take a look at some of the methods that other games have chosen in order to achieve this change of pace. One of the most common methods that I’ve seen is to introduce a timer of some kind.
(mechanical spoilers for the end of Portal and Portal 2 follow)
Both Portal games, for instance, end with boss battles where the player must solve a series of portalling challenges in a limited amount of time. Apart from a bit of a forced mechanical trick at the end of Portal 2, both games don’t introduce any new mechanics at the end and instead have the player exercising basic puzzle skills that they have mastered earlier in the game, with most of the challenge coming from the time constraint.
(end Portal spoilers)
The problem with puzzle games having time-constrained challenges is that they can devolve into a sort of worst-case scenario if you’re not very careful about designing them. If the puzzles are too much of a challenge or the time limit is too aggressive, players may find themselves repeating one of the least replay-able forms of gameplay besides horror.
(I mean, I’m a huge fan of puzzle games, but it’s an obvious fact that you often get much more out of replaying action games due to the dynamics of the gameplay than you get out of replaying a fixed set of puzzles, even in a fantastically well-designed puzzle game.)
(mechanical spoilers for The Witness follow)
One possible way of resolving this problem of repeatability is to introduce dynamics into the puzzle gameplay. The Witness does this with procedurally generated puzzles both in a small subsection of the Mountain ending, and in large form in its hidden Challenge area. Although the player must repeat the Challenge many times in order to succeed, because the puzzles are different each time, the player is never doing the exact same set of gameplay events through their many attempts.
(As a side note, if we consider The Challenge to be one of the endings, The Witness actually has three different endings: The meta-puzzle gauntlet inside the mountain, the time-limited challenge, and the sky lounge ending. Perhaps The Witness is “covering all the bases”, having multiple endings which might satisfy different players in different ways.)
(end The Witness spoilers)
There are lots of different approaches that have been attempted with puzzle game endings, and I won’t rule out incorporating some aspects of what other games have done into the ending for Taiji, but it is my plan right now to attempt something that I have not seen done before.
With that said, it is a large design and tech challenge and it is still in the nascent stages as of the writing of this article. But if I can pull it off, I think I will have created something that I personally can be satisfied with.
Been a little busy with various things, including dealing with my girlfriend’s dog having gotten run over. He’s okay but with a broken hip. Somehow, getting a dev log post out in time for the end of November totally slipped my mind. In any case, if you haven’t been keeping up with the video dev logs. Now would be a good time. The latest one is a bit beefy:
With that said, I’d like to dive a bit more deeply into what was involved in getting the save game hitch down to an acceptable level. As of writing this post, There’s still a hitch doing the actual saving, so the job is really only halfway done. However, I did do some work to get screenshot saving down to an acceptable level, and I think that’s a problem that many other games have, so it may be more useful to cover it in detail.
If you just want a decent solution to the problem, then feel free to skip to the end of the article to the section labeled “The Solution” and take a look at the code posted there. For the rest of you interested in hearing my journey to get there, read on!
The Problem
So why are we wanting to save screenshots as part of our save game routine? Well, the answer here is pretty simple, which is that we want the load game menu to show a screenshot of where the player was when they last saved. That way they can easily tell whether they are picking the right file to load:
Unity’s API really only gives you a few functions to handle taking screenshots. The first one and the easiest to use is ScreenCapture.CaptureScreenshot. It’s a simple to use function that takes a screenshot and saves it to a png file. This is great, right?
The problem is that it causes a massive lag spike. The peak of this single frame spike is close to 66 milliseconds. Needless to say this is unacceptable for a game that is targeting under 16.66ms per frame (and don’t even get me started about 8.33ms 120FPS which is apparently so impossible that Unity didn’t see fit to label it in this graph)
That’s an improvement, however we are still exceeding 33ms, which is slow enough to cause a noticable hitch even if the game were locked at 30fps. Additionally, this doesn’t even include the hit from writing out the file, as we only have a texture in memory.
Alright, so we should look into writing out this screenshot into a file. The easiest way to do this is the following:
So, obviously this is even worse than ScreenCapture.CaptureScreenshot but we should probably have expected that because the fine folks at Unity HQ know what they’re doing (perhaps), and because we’re just taking a function designed for putting a screenshot into a Texture2D and then we’re writing that out to disk.
However this isn’t actually the approach that I used, because I was actually unaware of both CaptureScreenshotAsTexture and CaptureScreenshotIntoRenderTexture when I initially went about writing this code. I don’t know if they are new API additions or if I am just a bit slow. Either way they both got ignored for no good reason. They are perfectly fine approaches for certain cases, but with that said I probably wouldn’t have stumbled upon my ultimate solution if I had known about them. Instead, my approach was using Texture.ReadPixels.
ReadPixels requires implementing in a coroutine delayed to WaitForEndOfFrame(). This seems alright as far as performance goes, not quite under the 60FPS threshold here, but an improvement. However, this graph is simply calling ReadPixels on a 3840×2160 framebuffer, without even writing that out to a file. If we take a similar approach to the way we did earlier, then we’d get the following code and the following performance characteristics:
Damn, so now we’re almost as bad as CaptureScreenshotAsTexture, while having made the code significantly more complicated. However, because we already need to do this ReadPixels process in a Coroutine, perhaps we can do it over multiple frames, so what might happen if we tossed in a few yield return‘s in there and spread that out over a couple frames, and while we’re at it, why don’t we put the file writing on its own frame?
Okay, performance implications are not always obvious in these high-level languages. We have almost an equivalent hitch across two frames now. Still, it seems like there has to be some fertile ground in this direction, even with all the obfuscation of a high-level language. So perhaps the issue is that we’re saving out the file on the main thread. Perhaps if we spin up a thread to write out the file?
Well, in spite of the fact that the above graph looks very similar, the scale on the left has changed, and now we are peaking a bit past 33ms rather than all the way to 66ms. So this is definitely an large improvement. However, we’re still not even halfway to 60FPS… One thing we could do pretty easily is to just add in even more yield return new WaitForEndOfFrame()s and read from the framebuffer over even more frames. However, because we are just reading from whatever the most recent frame was, if the scene changes much, this pretty easily can result in problems such as below:
Notice the visible seam down the middle of the frame. The issue is that the framebuffer is changing while we are trying to read from it. The performance of spreading this out over 5 different slices would look like the following:
Admittedly, I was a bit stuck here, but then someone suggested that I take a look into doing a copy GPU side so that I could simply read from the same framebuffer and not have any of these seams. I apologize for not remember who exactly it was who suggested it. In retrospect it seems pretty obvious, but as you might imagine I was pretty lost in the details at this point.
The easiest way to do this would be to use our earlier friend CaptureScreenshotIntoRenderTexture (I told you it’d come back!). As this will do exactly what the doctor ordered, capture the framebuffer into a RenderTexture. Unfortunately (or perhaps fortunately as the case may be), I didn’t know about this function and so I proceeded to dive into several ways of doing this type of thing, ultimately settling on CommandBuffers. (In the future, this will be the most outdated part of this article, as CommandBuffers are part of the legacy graphics pipeline for Unity and will most likely be removed.)
Okay, I’m going to save the code breakdown for a bit later, because otherwise I’d be putting a bunch of code in here that’s marginally different from the final code. But we’ll just say that we set up a CommandBuffer to copy the contents of the screen over to a second RenderTexture (which is really just a GPU-side texture). As part of that process, we have to blit it to a temporary buffer so that we can flip the image vertically. Due to some vagaries in how Unity handles its graphics pipeline, the image gets flipped after it is post-processed but before it is fed into the final display. We come out the other end with a RenderTexture, only it’s actually vertically oriented correctly, unlike CaptureScreenshotIntoRenderTexture, that just leaves it upside down.
This means that, unlike with our earlier staggered read, we can split the read from this RenderTexture across as many frames as we want without having any seams show up. The performance characteristics of doing this across 5 frames looks like the following:
Okay, so another improvement, but there still seems to be a large hitch at the end associated with getting the raw bytes from a Texture2D, and even the 5-frame-staggered readback from the framebuffer into the Texture2D is exceeding our 16ms frame boundary….enter:
The Solution
So, the ideal way to avoid this readback and conversion hitch is…maybe you can guess?
Well, if you didn’t want to guess, I’m gonna tell you anyway; tell the GPU to do the conversion and readback for us in an asynchronous way. The fact is that we will always end up with a bit of a hitch if we are using the CPU to tell the GPU to give us some texture data right now, because that means it has to stop or finish what it’s doing and focus entirely on that task. Instead, we can tell the GPU to give us that texture data “whenever it has a moment”, this is called a asynchronous readback request and can be done in Unity using the AsyncGPUReadback.Requestfunction.
Because this generates garbage, I instead chose to use the variant that uses NativeArray: AsyncGPUReadback.RequestIntoNativeArray. Note that this does mean that we will want to make sure we dispose of the NativeArray when we are done with it. For my purposes, I really only dispose of the array and reallocate it if the resolution changes.
First the performance characteristics of this approach:
Ah, we are finally at something acceptable. You may notice the peak shows slightly above the 16ms line, so it’s clear there is still some hit from the async readback, however in practice the stutter is not noticeable. I may revisit this further before release to see if I can squeeze out a bit more performance here. But for now I am happy enough with this part of the equation. For Taiji, I still have to do some work to improve the actual writing of the save file, but the screenshot taking is “good enough to ship”, as far as I’m concerned.
The actual save file performance is the left spike, and the right is the screenshot taking
So, here’s a snippet of something resembling the final code that I used. This is not exactly a plug and play class, but should be a good basis for getting something working in your own projects. I tried to at least have everything necessary in the snippet:
string QueuedPath;
NativeArray<byte> imageBytes;
byte[] rawBytes;
Thread _encodeThread;
public Material screenshotFlipperMat;
Vector2 previousScreenSize;
CommandBuffer cBuff;
public RenderTexture screenRT, tempRT;
//Call this function whenever you want to take a screenshot
public void TakeScreenshot(string fileOutPath)
{
StopAllCoroutines();
StartCoroutine(SaveScreenshot(fileOutPath, Screen.width, Screen.height));
}
//Helper function that will be called later
void InitializeBuffers()
{
//We do some checks to see if the resolution changed and we need to recreate our RenderTextures
bool resChanged = (previousScreenSize.x != Screen.width) || (previousScreenSize.y != Screen.height);
previousScreenSize = new Vector2(Screen.width, Screen.height);
//The array is Screen width*height*3 because we are going to use a 24bit RGB format (TextureFormat.RGB24)
if(imageBytes.IsCreated == false) imageBytes = new NativeArray<byte>(Screen.width*Screen.height*3, Allocator.Persistent);
else if(resChanged)
{
imageBytes.Dispose();
imageBytes = new NativeArray<byte>(Screen.width*Screen.height*3, Allocator.Persistent);
}
if(tempRT == null || resChanged) tempRT = new RenderTexture(Screen.width, Screen.height, 24);
if(screenRT == null || resChanged) screenRT = new RenderTexture(Screen.width, Screen.height, 24);
//We build our command buffer, which includes a double blit using a special
//material (shader in article) so that we can flip the output from the backbuffer
//This double blit seems to be necessary because CommandBuffer.Blit will not allow us to blit using a material
//if we are blitting from the backbuffer (BuiltinRenderTextureType.CurrentActive)
if(cBuff == null || resChanged)
{
cBuff = new CommandBuffer();
cBuff.name = "ScreenshotCapture";
cBuff.Blit(BuiltinRenderTextureType.CurrentActive, tempRT);
cBuff.Blit(tempRT, screenRT, screenshotFlipperMat);
}
GetComponent<Camera>().AddCommandBuffer(CameraEvent.AfterImageEffects, cBuff);
}
//Function to dispose of our imageBytes from external classes
public void Dispose()
{
imageBytes.Dispose();
}
//It may be possible to do this in one frame instead of as a coroutine, but I have not tested
IEnumerator SaveScreenshot(string fileOutPath, int width, int height)
{
InitializeBuffers();
yield return 0;
Camera.main.RemoveCommandBuffer(CameraEvent.AfterImageEffects, cBuff);
QueuedPath = fileOutPath;
AsyncGPUReadback.RequestIntoNativeArray(ref imageBytes, screenRT, 0, TextureFormat.RGB24, ReadbackCompleted);
}
void ReadbackCompleted(AsyncGPUReadbackRequest request)
{
if(request.hasError) return; //We just won't write out a screenshot, not a huge deal
_encodeThread = new Thread(EncodeAndWriteFile);
_encodeThread.Start();
}
void EncodeAndWriteFile()
{
rawBytes = imageBytes.ToArray();
byte[] jpgBytes = ImageConversion.EncodeArrayToJPG(rawBytes, UnityEngine.Experimental.Rendering.GraphicsFormat.R8G8B8_UInt, (uint)Screen.width, (uint)Screen.height, 0, 75);
File.WriteAllBytes(QueuedPath, jpgBytes);
Globals.updateLoadGameMenu = true;
}
Additionally, you’ll need a shader to do the backbuffer flipping, so here’s something for that. Better could perhaps be done, but this is based off of an internal Unity copy shader, so maybe not much better: